This week I moved from UniFi to a new setup that included OPNsense on the edge to handle firewall, NAT, and other such tasks on the home network. Built in to OPNsense is a basic NetFlow traffic analyzer called Insight. Looking at this and turning on Reverse lookup something strange popped out: ~22% of the traffic coming in from the internet over the last two hours was from just two hosts: dynamic-75-76-44-147.knology.net and dynamic-75-76-44-149.knology.net.
While reverse DNS worked to resolve the IPs to hostnames (75.76.44.147 to dynamic-75-76-44-147.knology.net and 75.76.44.149 to dynamic-75-76-44-149.knology.net), forward lookup of those hostnames didn’t work. This didn’t really surprise me as the whole DNS situation on the WOW/Knowlogy network is poor, but it did make me more curious. Particularly strange was the IPs being are so close together.
To be sure this is Knology (ruling out intentionally-misleading reverse DNS) I used whois to confirm the addresses are owned by them:
NetRange: 75.76.0.0 - 75.76.46.255
CIDR: 75.76.46.0/24, 75.76.40.0/22, 75.76.0.0/19, 75.76.44.0/23, 75.76.32.0/21
NetName: WIDEOPENWEST
NetHandle: NET-75-76-0-0-1
Parent: NET75 (NET-75-0-0-0-0)
NetType: Direct Allocation
OriginAS: AS12083
Organization: WideOpenWest Finance LLC (WOPW)
RegDate: 2008-02-13
Updated: 2018-08-27
Ref: https://rdap.arin.net/registry/ip/75.76.0.0
My home ISP is Wide Open West (WOW), and Knology is an ISP that they bought in 2012. While I use my ISP directly for internet access (no VPN tunnel to elsewhere), I run my own DNS to avoid their service announcement redirections, so why would I be talking to something else on my ISP’s network?
Could this be someone doing a bunch of scanning of my house? Or just something really misconfigured doing a bunch of broadcasting? Let’s dig in and see…
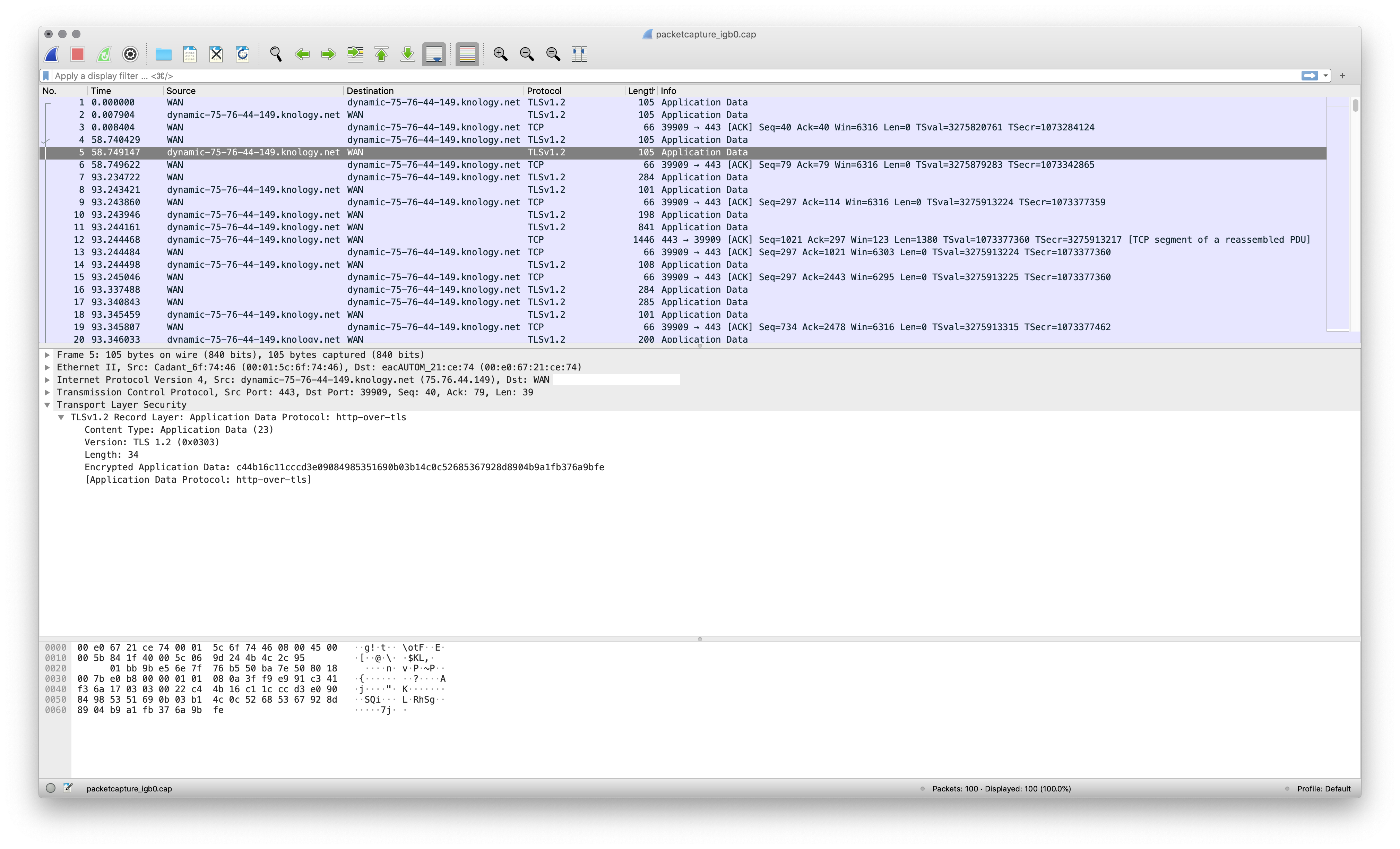
First I used the Packet capture function in OPNsense to grab a capture on the WAN interface filtered to these two IPs. Looking at it in Wireshark showed it was all HTTPS. Hmm, that’s weird…
A couple coworkers and I have Plex libraries shared with each other, maybe that’s it? The port isn’t right (Plex usually uses 32400) but maybe one of them are running on it in 443 (HTTPS)… But why the two IPs so close to each other? Maybe one of them are getting multiple IPs from their cable modem, have dual WAN links configured on their firewall, and it’s bouncing between them… (This capture only showed the middle of a session, so there was no certificate exchange present to get any service information from.)
Next I did another packet capture on the LAN interface to see if it’s a computer on the network or OPNsense as the local endpoint. This showed it’s coming from my main personal computer, a 27″ iMac at 192.168.0.8 / myopia.--------.nuxx.net, so let’s look there. (Plex doesn’t run on the iMac, so that’s ruled out.)
Conveniently the -k argument to tcpdump on macOS adds packet metadata, such as process name, PID, etc. A basic capture/display on myopia with tcpdump -i en0 -k NP host 75.76.44.149 or 75.76.44.147 to show all traffic going to and from those hosts identified Firefox as the source:
07:39:57.873076 pid firefox.97353 svc BE pktflags 0x2 IP myopia.--------.nuxx.net.53515 > dynamic-75-76-44-147.knology.net.https: Flags [P.], seq 19657:19696, ack 20539524, win 10220, options [nop,nop,TS val 3278271236 ecr 1535621504], length 39
07:39:57.882070 IP dynamic-75-76-44-147.knology.net.https > myopia.--------.nuxx.net.53515: Flags [P.], seq 20539524:20539563, ack 19696, win 123, options [nop,nop,TS val 1535679857 ecr 3278271236], length 39
Well, okay… Odd that my browser would be talking so much HTTPS to my ISP directly. I double-checked that DNS-over-HTTPS was disabled, so it’s not that…
Maybe I can see what these servers are? Pointing curl at one of them to show the headers, the server header indicated proxygen-bolt which is a Facebook framework:
c0nsumer@myopia Desktop % curl --insecure -I https://75.76.44.147
HTTP/2 400
content-type: text/plain
content-length: 0
server: proxygen-bolt
date: Sat, 16 Jan 2021 13:22:57 GMT
c0nsumer@myopia Desktop %
Now we’re getting somewhere…
Finally I pointed openssl at the IP to see what certificate it’s presenting and it’s a wildcard cert for a portion of Facebook’s CDN:
c0nsumer@myopia Desktop % openssl s_client -showcerts -connect 75.76.44.149:443 </dev/null
CONNECTED(00000003)
depth=2 C = US, O = DigiCert Inc, OU = www.digicert.com, CN = DigiCert High Assurance EV Root CA
verify return:1
depth=1 C = US, O = DigiCert Inc, OU = www.digicert.com, CN = DigiCert SHA2 High Assurance Server CA
verify return:1
depth=0 C = US, ST = California, L = Menlo Park, O = "Facebook, Inc.", CN = *.fdet3-1.fna.fbcdn.net
verify return:1
[SNIP]
As a final test I restarted tcpdump on the iMac then closed the Facebook tab I had open in Firefox and the traffic stopped.
So there’s our answer. All this traffic is to Facebook CDN instances on the Wide Open West / Knology network. It sure seems like a lot for a tab just sitting open in the background, but hey… welcome to the modern internet.
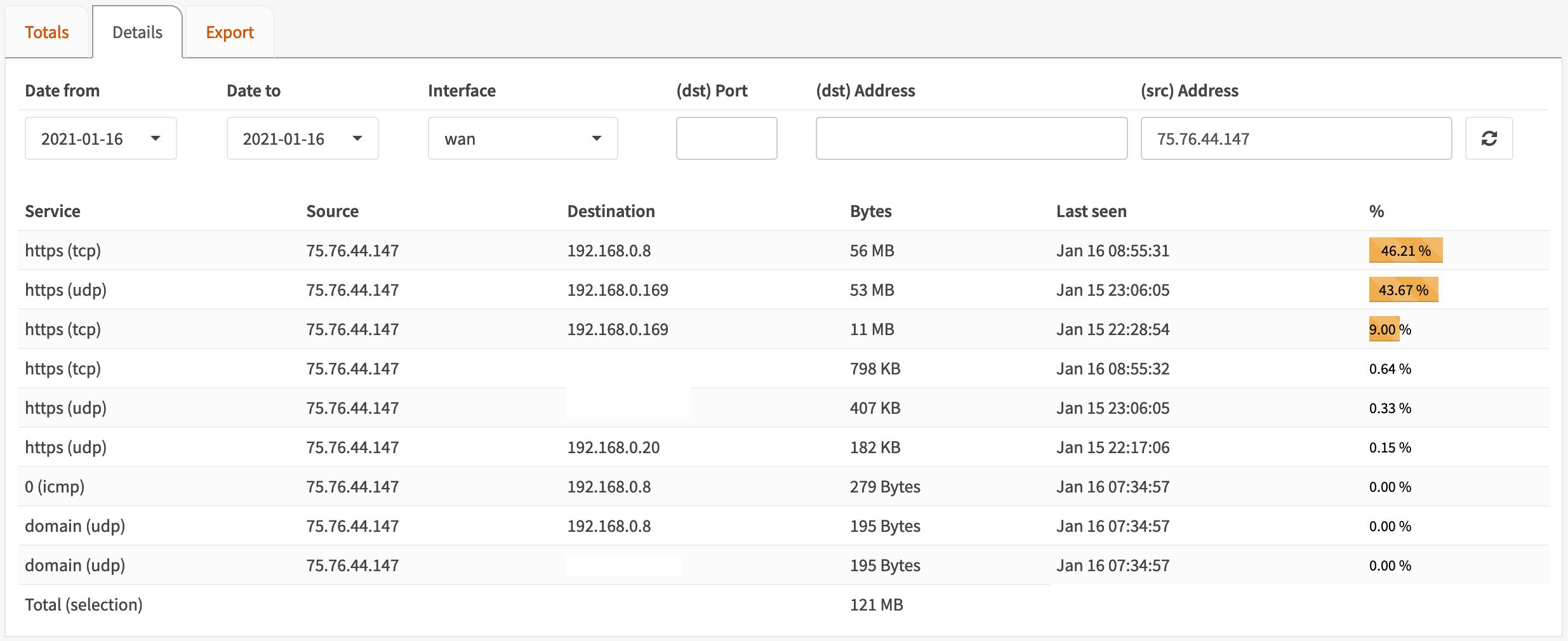
I could have received more information from OPNsense’s Insight by clicking on the pie slice shown above to look at that host in the Details view, but it seems to have an odd quirk. When the Reverse lookup box is checked, clicking the pie slice to jump to the Details view automatically puts the hostname in the (src) Address field, which returns no results (it needs an IP address). I thought this was the tool failing, so I looked to captures for most of the info.
Later on I realized that filtering on the IP showed a bunch more useful information, including two other endpoints within the network talking to these servers (mobile phones), and that HTTPS was also running over UDP, indicating QUIC.
(Bug 4609 was submitted for this issue and AdSchellevis fixed it within a couple hours via commit c797bfd.)






{kind=link}
{kind=link}
{kind=link}