php-cgi hung as sbwait with lighttpd on FreeBSD
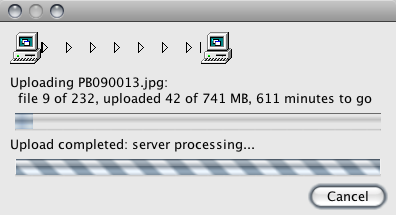
When uploading a quantity of photos to my gallery I like to use a tool like Gallery Remote to make it go easier. However, since moving to banstyle (photo gallery retired) (and a newer version of FreeBSD and lighttpd and PHP) I’ve had Gallery Remote regularly hang at that “Upload completed: server processing…” message. It seems to happen after a few (typically two to five) images have been uploaded.
This problem has been bothering me for a while, but I was able to work around it by scping the files to the server then adding them locally, which doesn’t have this problem. Now that I have a bunch of photos from the UK trip to upload, I want to be able to use Gallery Remote again. This morning I set to getting working, but I seem to have failed.
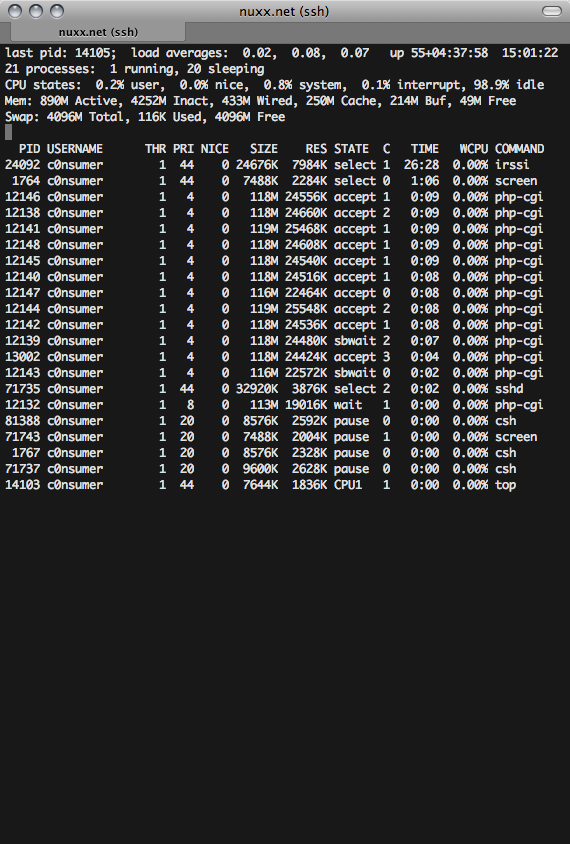
In short, what happens is that after an upload hangs I see one of the php-cgi processes stuck in a status of sbwait, as can be seen in this screenshot:
81073 c0nsumer 1 4 0 116M 20988K sbwait 3 0:01 0.00% php-cgi
Digging around I found this thread where someone else indicates that they are having the same problem, and only on SMP boxes. (Note: banstyle.nuxx.net is four-way SMP using SCHED_ULE.) I also came across this report to the lighttpd folks regarding this issue. The consensus seems to be that when using a config such as mine, with PHP as a FastCGI and lighttpd, this occasionally happens. I’ve seen no reports of the issue occurring under Apache.
Since I’m able to reproduce the problem I did so, attached gdb to the seemingly hung php-cgi process, and grabbed a backtrace:
(gdb) bt
#0 0x00000008010a476a in read () from /lib/libc.so.7
#1 0x000000000057d5fc in fcgi_read ()
#2 0x000000000057e306 in sapi_cgi_read_post ()
#3 0x00000000004c84a4 in fill_buffer ()
#4 0x00000000004c88b5 in multipart_buffer_read ()
#5 0x00000000004c9c08 in rfc1867_post_handler ()
#6 0x00000000004c6ee5 in sapi_handle_post ()
#7 0x00000000004cc30c in php_default_treat_data ()
#8 0x00000000004cc7eb in php_hash_environment ()
#9 0x00000000004bff47 in php_request_startup ()
#10 0x000000000057f8c6 in main ()(gdb) f 0
#0 0x00000008010a476a in read () from /lib/libc.so.7
(gdb) info frame
Stack level 0, frame at 0x7fffffff9c50:
rip = 0x8010a476a in read; saved rip 0x57d5fc
called by frame at 0x7fffffff9db0
Arglist at 0x7fffffff9c40, args:
Locals at 0x7fffffff9c40, Previous frame's sp is 0x7fffffff9c50
Saved registers:
rip at 0x7fffffff9c48
Based on the input from some folks online, it’s looking like that is php-cgi doing what it’s supposed to and just waiting for more data, which means that the problem is likely somewhere in lighttpd. I’m not really sure where to go from here, besides wait for the lighttpd folks to (hopefully) fix the problem. With any luck I’ll be able to update this post later on with a solution. For now I’m going to contemplate the difficulty of going (back, in many ways) to Apache.
For reference, I’m running lighttpd 1.4.20 and PHP 5.2.6, both installed from ports, configured as described in my article about running lighttpd with PHP as FastCGI with each user having their own PHP processes.
UPDATE: So, it seems that there is a fix for this which was suggested in the aforementioned bug report. Setting the option server.network-backend = "writev" along with the already set (in my case) server.event-handler = "freebsd-kqueue" in lighttpd fixes it. I’m not sure if both options are needed to resolve the issue, but it seems that the default setting for server.network-backend of write is confirmed as broken under FreeBSD 7.0-RELEASE with lighttpd <= 1.4.20.



{kind=link}
{kind=link}
{kind=link}
{kind=link}